





This MongoDB Tutorial is Part 2 in series of MongoDB Interview Questions. In this technical interview questions part, we will learn about more advanced topics related to MongoDB as NoSQL database. If you haven’t gone through the previous part, we will highly recommend to go through the previous one first and then move to these advanced Interview questions or topics on MongoDB. 
Getting Started MEAN Stack Tutorial Series
We already have covered other components of Full Stack JavaScript by cover the followings:
- AngularJS 1.x - Beginners to Professional.
- NodeJS - Learning the Practical way.
- AngularJS 2 - Learn by Example
- ExpressJS - Learn the Practical way - Releasing Soon
MongoDB Tutorial PDF version will be available later for download.
MongoDB Interview Questions Tutorial - From Beginner to Professional
- What is difference between Replication and Sharding? Can we achieve these two with MongoDB?
- In RDBMS there are functions available for min, max, count etc. for aggregation, are there any such functions available in MongoDB to achieve aggregation, explain each aggregation function with example?
- What is the composition/structure of ObjectId in MongoDB? Explain in detail each composing element.
- Explain GridFS in MongoDB? Give a practical example with source code for adding files to GridFS.
- How database relationship(1:1,1:N,N:1) is maintained in MongoDB? Explain with proper example
- What are atomic operations? How automicity is achived in MongoDB, explain with example.
- Explain MapReduce in MongoDb with example?
- What is capped collection in MongoDb? How capped collections are created in MongoDb?
- Give a practical example of creating Capped Collection in MongoDB?
- Does MongoDb support regular expressions? If yes, explain searching in MongoDb with regular expression. Implement an example.
What is difference between Replication and Sharding? Can we achieve these two with MongoDB?
Replication:
Replication as the name suggests, is the process of synchronizing data on multiple servers. In other words the copy of data will be maintained on different servers. Replication gives us the surety that the data is available on more then one server. This increases the availability of data, since data will be available on more then one server. It helps us to fight against data loss since in case of fail-over of server data will be available on other servers.
With replication in place there will be no data loss, also the availability of data will be 24/7, we don’t need to worry about downtime since there are replicas and we can use any of the server to read. Data will be read scalable, that means since there are more than more copies of same data, app can use any server instance to read.
Replication with MongoDB:
In mongodb replication is achived by replica sets. A replica set is a group of mongodb instances that have the same data. In replica set one node is primary node that receives all data and primary node then replicates the data to secondary nodes. There can be only one primary node in replica set.
A replica set is a group of two or more nodes, within which there will be one primary node and other nodes will be secondary nodes. Data is typically replicated from primary node to secondary nodes. At the time of failover a new primary node is automatically selected and connection is established to the new primary node.
The above diagram demonstrates how replication is performed in MongoDB.
Lets see how replica sets are created?, below is the syntax for the same:
|
1 |
mongod.exe --dbpath “c:\data\db” –replset “instance_name” |
We need to shutdown the mongodb instance first and then again execute this command with the replica set name. -replset is the command flag that is need to start mongodb with replicaset.
Once server is started, from mongodb client we need to fire a command that is rs.intiate() to initiate a new replicaset.
Sharding:
Sharding is the concept of splitting data across multiple machines. It basically splites data among smaller datasets and stores across machines. At times querying against huge data set needs a very high cpu utilization. To tackle this situation Mongodb comes up to a concept of sharding, which actually splits the data across multiple machines. This can be a large collection of shards but logically all shards works a collection.
Components:
Components of a shard typically include the following:
- Shard: Shard is a mongodb instance which holds the subset of data.
- Config server: Config server is also a mongodb instance which holds information about the mongodb instances which holds shared data.
- Router: Again a mongodb instance which is responsible for directing the commands sent by server.
This is all about Replication and Sharding in MongoDB.

In RDBMS there are functions available for min, max, count etc. for aggregation, are there any such functions available in MongoDB to achieve aggregation, explain each aggregation function with example?
Aggregation is the concept of processing data records and return aggregated result. Like RDBMS aggregation is possible as well in MongoDb as well. Ofcoures here we will not be using select count(*) type of syntaxes but the same will be achieved by functions available in MongoDb. Aggregation group multiple records/documents from a collection and perform operation on these records and return a computed result. In MongoDb aggregate() method is used to perform aggregation. Below is the syntax for the same:
|
1 |
db.<collection_name>.aggregate(<aggregate_function>) |
Lets add some records in the collection ScienceBooks, with following schema:
|
1 2 3 4 5 |
{ BookName : <BookName> Category : <Book_Category> Price : <Book Price> } |
To demonstrate this, we have created a records file with some data and imported to database. Below is the content of the file:
|
1 2 3 4 5 6 |
{"BookName" : "HeadFirstJava", "Category" : "ComputerScience", "Price": "100" } {"BookName" : "HeadFirstDesignPattern", "Category" : "ComputerScience", "Price": "130" } {"BookName" : "SpringInAction", "Category" : "ComputerScience", "Price": "400" } {"BookName" : "OrganicChemistry", "Category" : "Chemistry", "Price": "110" } {"BookName" : "PhysicalChemistry", "Category" : "Chemistry", "Price": "190" } {"BookName" : "InorganicChemistry", "Category" : "Chemistry", "Price": "70" } |
Lets import this file now and see the output:
The code above demonstrates the import and find from books collection:
Count():
Now our books collection which is in BookStoreDB has few records , with which we can play around through aggregation :
Lets suppose we want to find how many books are in Chemistry Category and how many in ComputerScience category, similar to select Category, count(*) from books group by Category;
min() :
Now lets suppose we want to get the minimum price for each category, below is the code for the same:
|
1 2 3 4 5 6 7 8 9 |
db.books.aggregate( [ {$group : { _id : "$Category", min_price : {$min : "$Price"} } } ] ); |
Executing this code will result in the minimum price of book for both the categories.
max():
Similiarly suppose we want to get the maximum price for each category, below is the code for the same:
|
1 2 3 4 5 6 7 8 9 |
db.books.aggregate( [ {$group : { _id : "$Category", min_price : {$max : "$Price"} } } ] ); |
Executing this code will result in the maximum price of book for both the categories.
sum():
Now if we want to have the sum of price of all books available in our book store, below will be the code for the same:
|
1 2 3 4 5 6 7 8 9 |
db.books.aggregate( [ {$group : { _id : "$Category", min_price : {$sum : "$Price"} } } ] ); |
These all the basic aggregation RDBMS functions that MongoDb also supports and with the code examples.
What is the composition/structure of ObjectId in MongoDB? Explain in detail each composing element.
ObjectId in MongoDb plays a very special role. It associates with _id field, and MongoDb uses objectid as the default value of _id in documents.
As we know Object is of type BSON. Object is 12 byte bson type data structure. The composition/structure of ObjectId is as follows :
- The first 4 bytes represents the seconds since last unix time.
- The next 3 bytes after first four are the machine identifier.
- The next 2 bytes after the machine identifier are the process id.
- The last 3 bytes after machine identifier is some random counter value.
This represents the object id structure in a whole. To generate object id, MongoDb provides function as objectId(), syntax for the same is below :
|
1 |
ObjectId([SomeHexaDecimalValue]) |
Lets take example of creating ObjectId:
|
1 |
obj_id = new ObjectId() |
The above statement will return the unique hexadecimal string containing object id as below:
|
1 |
ObjectId("6539h6hgt8721s97w45798j7") |
We can also provide some unique hexadecimal string object id of 12 byte in method parameter, lets take an example:
|
1 |
Custom_obj_id = new ObjectId("2569j6hgt8621s97w45798j7") |
There are some methods of ObjectId, below are the details :
- str : provides string representation of object id.
- valueOf() : returns the hexadecimal representation of ObjectId.
- getTimeStamp() : returns the creation timestamp of objected.
- toString() : returns the string representation of ObjectId in the “ObjectId(haxstring)”
Explain GridFS in MongoDB? Give a practical example with source code for adding files to GridFS.
Let say we need to store large data files in MongoDb, how to do that, in a single document ? No, since MongoDb has limitation for a document to have maximum size of 16MB. Now how about storing data which has size more than 16 GB. In such scenarios GRIDFS comes to rescue us. GridFs is a MongoDb specification that enables us to store data that has size more than 16MB. These large files can be some audio files or large images or might be a video file. In a way it is a kind of file system storage but still the data is store in MongoDb collections.
GridFS divides a large record ie a file into small chunks and it stores these chunks of data in documents, and each document has the maximum size of 255 kb.
GridFs uses two collections to store the large data, one collection is used to store the file chunks and other one is to store its metadata. These two collections are known as fs.files and fs.chunks to store file metadata and chunks.
When we want to retrieve the large dataset from MongoDb server, the MongoDb drivers reassembles the data from chunks and returns the data to calling function.
Syntax to store file using GridFs is:
|
1 |
mongofiles.exe -d <database_name> put <file_name> |
To find the document in the database, find() method is used, below is the syntax for the same:
|
1 |
db.fs.files.find({filename : <file_name>}) |
Lets take an example to store a large file in mongo db server :
To store a file we need to traverse through the bin directory of mongodb installation:
Lets suppose we need to store the below file that is around 52MB in size.  Lets try to store this file using GridFS.
Lets try to store this file using GridFS.
As we can see the BookStoreDB has now the video file that is of 52 mb, and the file has been stored.
Lets try to find the file that we have just stored:
As we can see in the output, we just got the file data from GridFs that we have stored.
To get all the chunks present, we can use the following command:
Running this file will return all the chunks. Notice we have used the files_id, as we got in the find command with chunks.
How database relationship(1:1,1:N,N:1) is maintained in MongoDB? Explain with proper example.
Like relational database where records are relationally referenced in different tables maintaining the relationship as one to one (1:1), one to N (1:N), N to one (N:1), N to N (N:N). Relationship in MongoDB represents the way documents are logically connected to each other. In MongoDb these relationships are modeled in two ways :
- Embedded
- Referenced
Lets take an example of our BookStore application, where user can take one to N books on rent. Here in our database this relationship will be relationship will be in One to N (1:N).
Lets try to achieve this using the Embedded approach: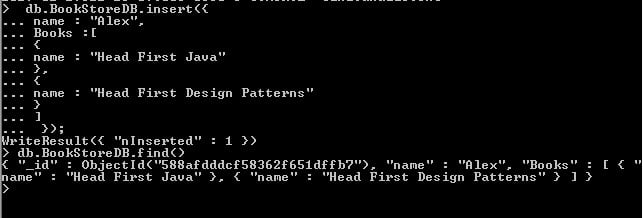
As we can see in the example above we have inserted record with embedded approach, Here Alax user has two books Head First Java and Head First Design Patterns. In the embedded approach a single documents have the embedded records referenced. This approach have all the related data in the single document and if we need to find the whole document below will be the query to find one:
As we can see from the query above, it resulted us the whole document that we have inserted.
So in essence in the embedded approach, we have all the related documents/records in a single document.
Now let’s move to another approach that is Reference approach :
In this approach instead of having all document in a single document, we will have separate document and these are referenced with ObjectId.
As we can see in the example above, the object ids are just dummy ids for demo purpose. In the next section we will be taking an example wherein we will insert two separate book records and we will be referencing these documents through their ObjectIds.
Lets try to store the Book documents and try to find to get the object id with which we will be referencing:
In the example above we have inserted two records for two books, Head First Java and Head First Design Pattern. And in the next step we have tried to find the records and we can see the inserted records in the BookStoreDB.
Now lets try to reference the documents to a user with reference approach:![]()
This way we can store the records in referenced way in MongoDB.
What are atomic operations? How automicity is achived in MongoDB, explain with example.
Atomicity is an important aspect of database that comes under ACID concept. NoSql databases have some difference with respect to handle atomicity as compared to traditional relational database systems and so as MongoDB. Lets try to understand what automicity is : Automicity is a concept where in while updating some records in the database either all records should update in a transaction or no record should update. Basically we can refer it to an atomic transaction. What automicity garuntees is either all records of database will update in a transaction or no record will update, that prevents the partial updation.
MongoDb also supports automicity but as we discussed in some different manner. In MongoDB there is a constraint that only one document can be updated as part of a single transaction. There can be multiple documents in a single document and it can be updated keeping automicity, but if there will be multiple documents then automicity cannot be achieved in MongoDb, so in essence we can achieve automicity in MongoDb but on a single document.
So what if we still we want to achieve automicity on multiple documents, here you need to use two phase commit to achieve the same. But the recommended approach to achieve automicity is to have the embedded documents, ie. To have all the related documents in one place.
Lets try to understand the same with help of an example:
Lets suppose we have a book store and in our bookstore we are maintaining the total number of “Head First Java” books and the remaining number of books, also at the same time we are maintaining the record about the user who bought the book. So a buy operation from frontend, and the below actions will performed at backend :
- Decrese the available number of books by 1.
- Update the Buyer Information with the user details who bought this book.
Below is how the document looks like for the same:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "_id":"sr888377jjfjj3333", "book_name":"Head First Java", "total_books":100, "book_category":"Computer Science", "available_books":78, "Buyer Information": [ { "name":"Alex", }, { "customer":"Jimmy", } ] } |
So as we can see we have embedded the Buyer Information document with this in order to achieve atomicity. Whenever a buy book request will made from front end, at database side first it will check for the available number of books, if the available number of books is greater than 0, then the available books count will be decreased by one and the buyer information will be updated in the embedded document, Buyer Information that is embedded with the main document.
To update a document in MongoDb we will use findAndModify() method. Let’s take an example with the scenario above how we can use the findAndModify() method:
|
1 2 3 4 5 6 7 |
>db.BookStoreDB.findAndModify({ query:{_id: "sr888377jjfjj3333" , available_books:{$gt:0}}, update:{ $inc:{available_books:-1}, } }) |
The above code fragment first checks that if the available books are greater then zero, if the count is greater than zero than in the update part first decrease the count of available books by 1 and add the buyer information in the Buyer Information embedded document.
Explain MapReduce in MongoDb with example?
MapReduce is a concept of processing large set of data and return an aggregated result.
From MongoDb official site :
“Map-reduce is a data processing paradigm for condensing large volumes of data into useful aggregated results. For map-reduce operations, MongoDB provides the mapReduce database command.”
MapReduce is usually used where we need to process large datasets.
Lets go through the map reduce command in MongoDb:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
db.runCommand( { mapReduce : <Collection_Name> map: function() { //map function }, reduce: function(key,values) { //reduce function }, { out: collection, query: document, sort: document, limit: number } }) |
Lets go through each term used in command one by one :
map, maps value with key and emits a key,value pair.
reduce, reduces the key value pair and group all the values with same keys.
out, indicates the location to put the result.
query, indicates if there is any thing that needs to be selected based on some criteria.
sort, Boolean field, indicates that the result needs to be sorted or not.
limit, is the number of documents that needs to be returned.
Let’s now try to understand the same with help of an example. Consider a scenario where have a online portal and we are getting a kind of items from different companies. Typically our document structure is like:
|
1 2 3 4 5 |
{ Item_name : “Sony Xperia-z”, Category : “mobile_phone”, Company : “Sony” } |
Using this type of recordsets we will use map reduce to do some stuff. Lets first insert some records in our online portal database.
So our onlineportal database is ready and we have populated some records for MobilePhone category. Now Lets play with map reduce features :
Suppose we want to count the number the items from each company, below is how we will write command for the same using MapReduce: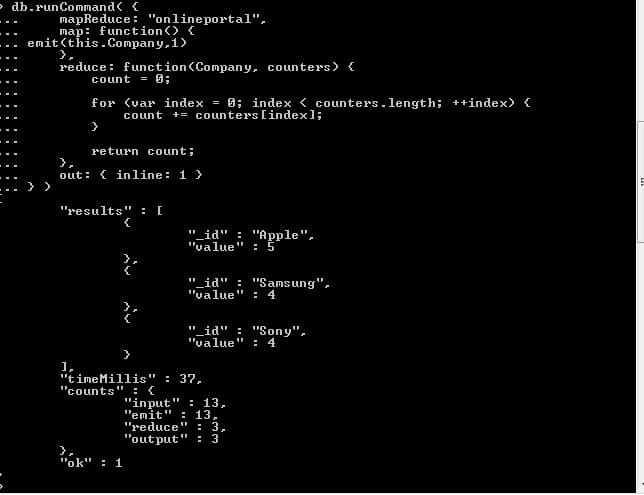
As we can see, we wrote a command used company in map and used the key in reduce function, with a counter. In results section we got the expected result that Company Apple have 5 products/items in our db, Samsung has 4 and sony has 4.
Now in another requirement we want to count the number of MobilePhones that have Price greater then 40000, lets see how we can achieve this :
We will use query in this case and we will try to find out the records that have price greater then 40000. Below is the example:
As we can see, we have the results now and in the way we wanted, Apple has 2 phones that have Price greater then 40000, Samsung has 1 and Sony has 3. If you give a close look at the command that we have used here from the last example we have just added a new thing here that is query, and added the condition what we required and map reduce gave us the results in a flash.
This way we can process a very large dataset in our application using MapReduce.
What is capped collection in MongoDb? How capped collections are created in MongoDb?
Capped collection is a special kind of collection in MongoDb, what can have limit on collection storage. That means in this collection we can restrict the size of collection or we can put limit on size of collection, these special type of collection is named as Capped Collection.
Lets take a look at the syntax of creating capped collection:
|
1 |
db.createCollection(<Collection_Name>, {capped: Boolean, autoIndexId: Boolean, size: Number, max : Number}) |
The syntax is near about same as the syntax of creating collection. Lets understand the syntax first :
Collection_Name : Name of collection that needs to be created as capped collection.
capped : Capped is the Boolean flag, true if the collection needs to created as capped collection, by default the value is false.
autoIndexId : Boolean flag, used for autoindexing, if true indexes will be created automatically, false will say indexes will not be created automatically.
size : Size parameter says the max size of documents in bytes, it is mandatory field in case of capped collections.
max : max parameter says the max number of documents allowed in a collection. Size is given preference over size.
MongoDb provides a method isCappped() to check if the collection is capped or not. Below is the syntax for the same:
|
1 |
db.<Collection_Name>.isCapped() |
Give a practical example of creating Capped Collection in MongoDB?
Let’s try to create a capped collection and try to simulate with some number of documents:
Consider a scenario wherein we have a bookstore application and we are logging the user data, and we want this data shouldn’t go over 3 documents. So we will be creating a capped collection that will have of capped collection type and have the restriction of keeping 3 documents, just to simulate this our example will not have the actual log data but just the documents having dummy data.
Lets first start with creating a capped collection in our BookStoreDB:

Here we have created a collection named Logs as capped collection and provided the max document as 3 and max size as 200Bytes. In next command we have checked with the method isCapped() that if the collection is capped or not.
Let’s try to insert data in our collection: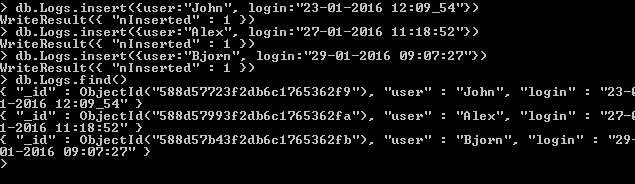
So till now we have created a capped collection with max size of 3 documents, we have inserted three documents and the same reflected in the find command. Now since the collection is size of 3 documents and its now reached its threshold, now if we add another document, the oldest one will be overridden by newer one.
Let’s create a new record and try to find the documents in the collection:

So we have inserted a new document, lets try to list the documents now:

So as we can see the old document of user John is overridden now, since the Logs collection is capped collection and of the max size of 3 documents.
Capped collections are useful for log files, these collections only allow updates on original document size which ensures that the document will not change its location on disk. The same is also a disadvantage as well since if the update go beyond the size then the update will fail. One more disadvantage is that we cannot delete a document from capped collection.
Does MongoDb support regular expressions? If yes, explain searching in MongoDb with regular expression. Implement an example.
Regular expressions are used in software applications among various languages to find pattern from a string or from a document or from database. MongoDb also have support for regular expressions. In relational database systems we use like and % for pattern matching in string. In MongoDb as well the same can be achieved using pattern matching as well as using regular expressions.
Lets understand the same with example:
To start with this we will add some data in a collection. In our BookStoreDB, we are going to add some books with name, author and isbn number.
So in our allbooks collection, we have inserted some records for books. Now lets try to search in our collection using regex :
Syntex to search some string in document from json is:
|
1 |
db.<Collection_Name>.find( {<fieldname> : { $regex : <Pattern> }} ) |
Lets understand the syntax :
Collection_Name is the name of collection under which we need to perform searching.
FieldName is the name of key, whose value needs to be find with regex.
$regex is the regular expression syntax in MongoDB.
Pattern is the pattern which needs to be search.
Lets apply the syntax and try to search from the allbooks collection, where we need to find the book name which have “Java”.
As we can see we got the results that have value as Java.
Now there might be scenario where we need to search for exact string, let suppose we have one more book that has name as “JavaScript In Web”, and if we will try to apply our search we will get the same in result as well, since JavaScript have the Java word in it. To avoid such scenarios there are some special characters available in MongoDb that comes in action to rescue, there are $ and ^.
^ (Caret) used to make sure that the string should start with the character given in pattern whereas $ used to make sure that the string should end the character given in the pattern.
If we want to make our search case insensitive then we need to use $options with our search.![]()
If we don’t want to use regex for pattern matching, then there is another option available that is to use /<pattern>/ in find command, below is the syntax for the same: ![]() This is all about pattern matching using regex in MongoDb.
This is all about pattern matching using regex in MongoDb.
In this project-based course, you will build an entire Bookstore from scratch. You will be able to add, edit and delete books to the backend and customers will be able to browse, add and delete books from their cart as well as purchase it using Paypal.

Take this Course Online Now
Hopefully, this series of MongoDB Interview Questions with detailed answers including source code will be an ultimate source for Interview preparation. Next we are going to cover more MEAN Stack related topic, so keep in touch 🙂
Top Technical Interview Questions and Answers Series:
- Top 20 AngularJS Interview Questions
- Advanced Angualar2 Interview Questions
- NodeJS Interview Questions and Answers
- Top 15 Bootstrap Interview Questions
- Top 10 HTML5 Interview Questions
- Top 10 ASP.NET MVC Interview Questions
- Top 10 ASP.NET Web API Interview Questions
- Top 10 ASP.NET Interview Questions
- Comprehensive Series of ASP.NET Interview Questions
- Top 10 ASP.NET AJAX Interview Questions
- Top 10 WCF Interview Questions
- Comprehensive Series of WCF Interview Questions